Zero shot learning with CLIP
June 24, 2022
A fun property of machine learning is that this reasoning works in reverse too: If meaningful generalities can help you represent your data with fewer numbers, finding a way to represent your data in fewer numbers can often help you find meaningful generalities. Compression is akin to understanding and all that.
CLIP
CLIP is a semi-recent It’s from Jan 2021 so ancient in DL terms model from OpenAI that claims to be really good at zero-shot learning across a wide variety of tasks.
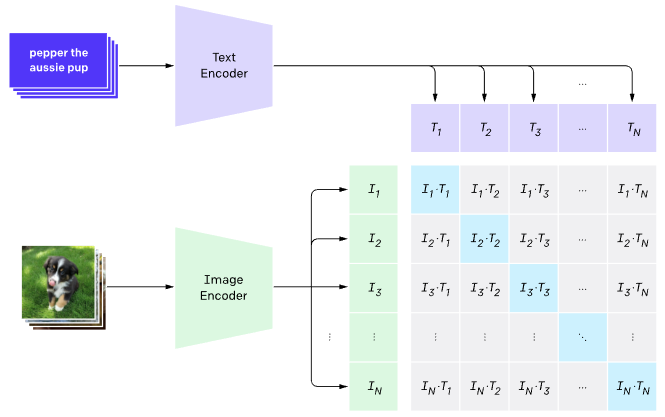
CLIP at training time.
At a high level clip takes in an image and a text prompt and it spits out a similarity between the two. Under the hood it consists of an Image and Text Encoder and it has been trained to essentially learn the embedding such that the dot product of the image and text embedding is the similarity.
The nice thing for us is we don’t have to think about what kind of transformer is used for what encoding. We can essentially treat CLIP as a black box: given an image and text give us a similarity. Or, alternatively give us the embeddings and let us do as we please.
I recently tried out CLIP on some data I can’t show you and I was surprised at how well it did on images that are bound to be very rare on the internet.
So, let’s see how CLIP does.
Yoga Pose Dataset
I wanted to keep things interesting, so I went to the internet’s premier source of weird and wonderful datasets: Kaggle. This yoga poses dataset consists of 5 poses with a few hundred images each.

To start, I tried three different prompt styles: first just the class names with “yoga pose” appended, second I cleaned up the class names so that warrior2 become warrior two, and third I google the proper Sanskrit Yoga names and used those.
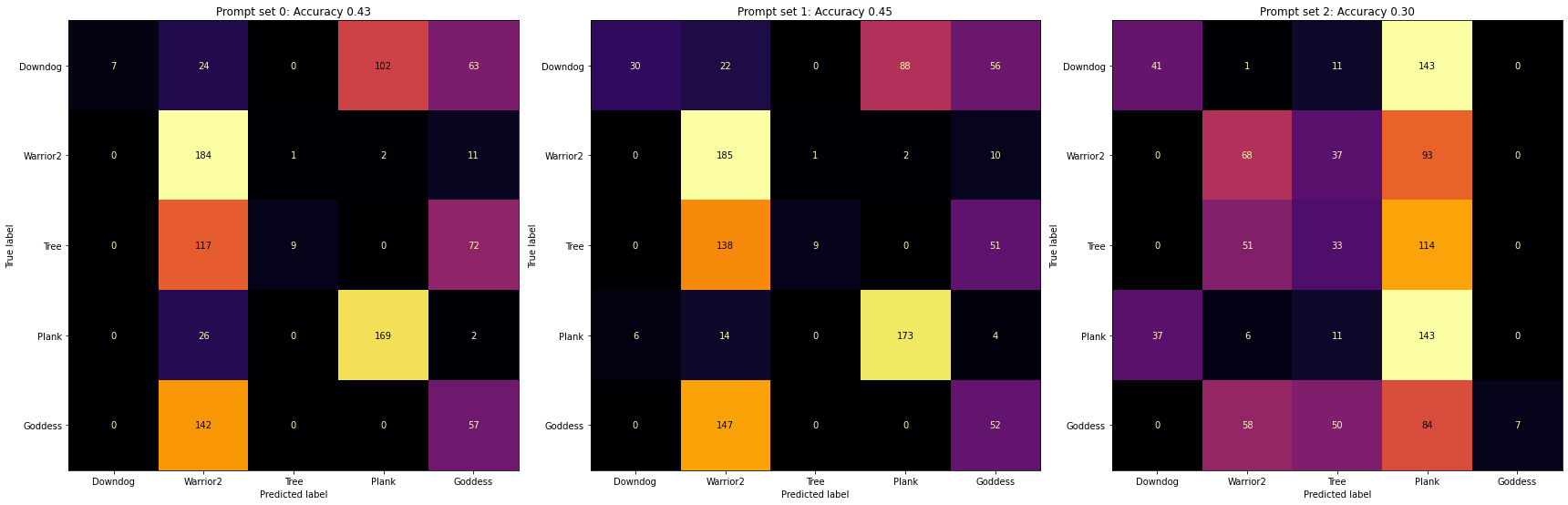
CLIP does OK on some poses Amusingly, does fine with warrior2 even though I was worried the class name was not great. but overall this wasn’t the best first showing. Now, we can jump into so good old-fashioned (hah) prompt engineering but there is one thing to consider first.
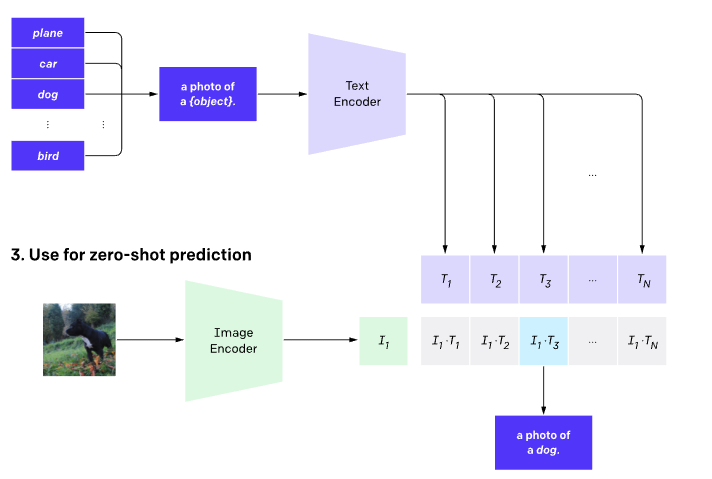
Note how the test time prompts are constructed.
In the
paper
OpenAI note that at test time they constructed prompts in the form “a photo of {object}”.
I was curious if maybe the model had learned this prompt style implicitly so I adapted my three prompt styles and re-ran the images though.
Doing so improved the results a fair amount and the errors are not completely unreasonable. For the most part it seems to do alright, just confuses the standing poses like warrior two, tree and goddess. To be fair to CLIP I would do terribly at classifying yoga poses (especially if you gave be like 20ms per image)
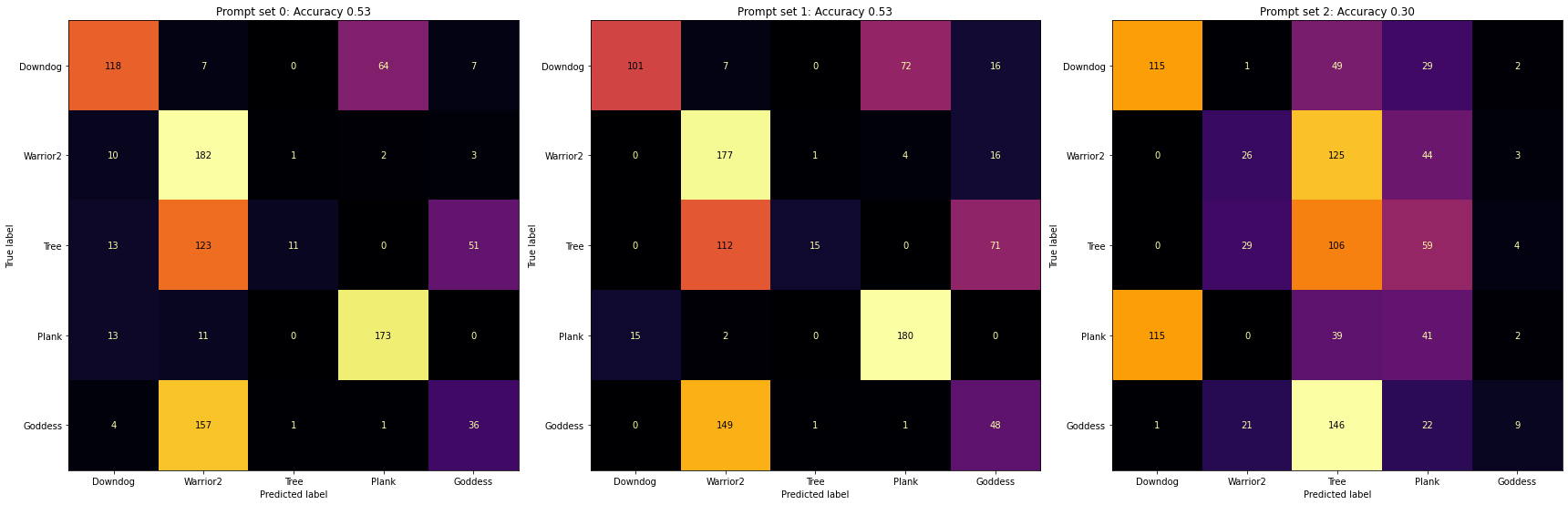
It is interesting to note, that despite being trained not to be, CLIP is still pretty sensitive to the prompts Quick, add prompt engineering to your LinkedIn now to get a head start on the five years of prompt engineering experience required train. . I’m curious if there’s a quicker way to dial this in though. Something like style transfer where you try optimise your inputs to maximise the score? I’m not sure transformers like that kind of thing but it could be fun to try.
Something easier
OK, fine, let’s try a softball. This scene dataset is the kind of easy-peasy DL problem that you could probably train something from scratch in an afternoon for. But, the whole point of zero-shot is that we don’t have to do any work at all.

For this one I also went with 3 different prompt sets: first up just class names, second a photo of classname, and third a photo of classname landscape.
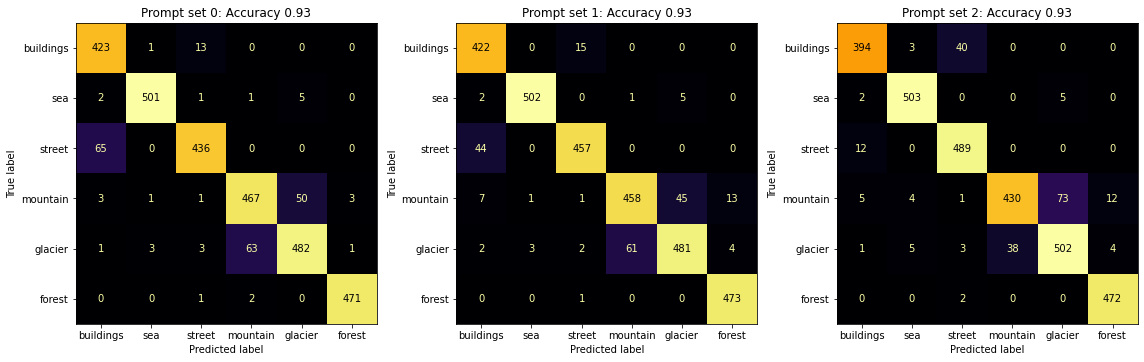
It is interesting that the “a photo of” prompts are better. It really does seem like CLIP has some dependence there. Otherwise, things look good. If we look at the misclassifications, I’m mostly on CLIP’s side here.

It is pretty cool that you can get 90+ accuracy in a task having done precisely zero work.
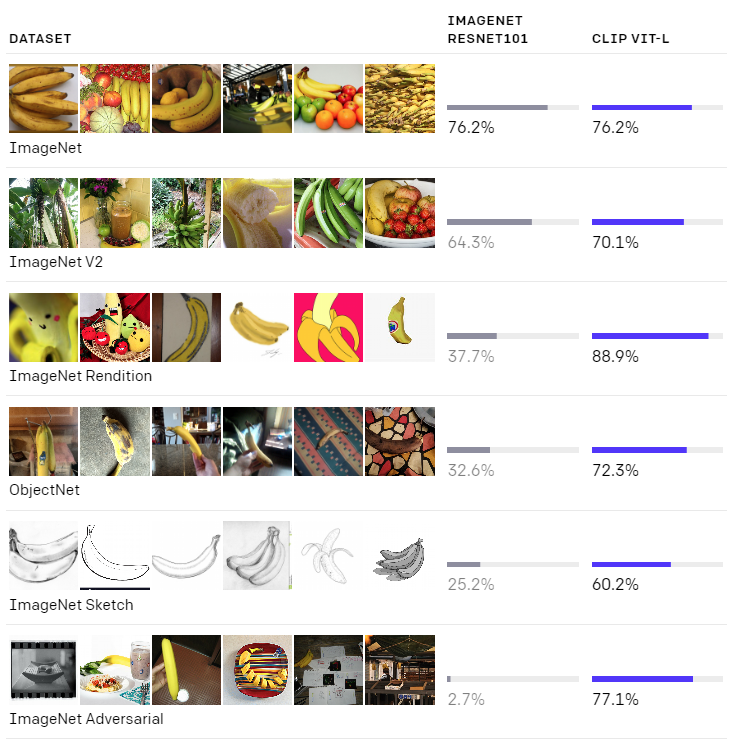
Verifying the banana claims
Lastly, I had a look at this fruits dataset, it looks like undergrad project or something but the OpenAI blog post does make some banana related claims.
Also this is something I could see popping up, where you get a small collection of product/industrial images and need to bang out a quick classifier.

Some of these are pretty tricky, I’m not sure how well I would do, stuff like apple hit vs apple rotten is maybe a bit unfair. Also that pear is pretty rotten as well. Anyway,
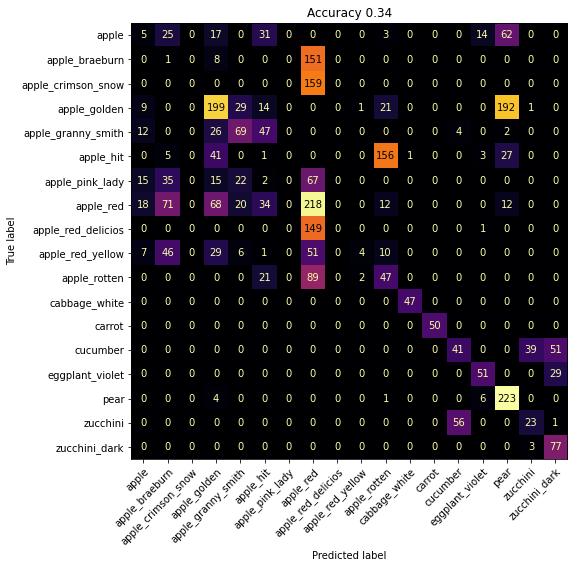
Yeah, that’s not too bad all things considered. Complete chaos in the apple quadrant and some cucumber/zucchini, golden apple/pear mixups but that’s not unreasonable.
It was at this point I realised I had left the prompts as “a photo of classname” which meant this was with the “apple_braeburn” style class names with the underscores still.

Fixing that somehow that made things worse though, so buyer beware.
Conclusion
Depending on your dataset you could probably get a ton of mileage out of CLIP in a zero-shot setting. But I feel like a lot of the time transfer learning a resnet Or convnext! is gonna get you further. I’m still super impressed though and it’s crazy that you can get 90+ accuracy on tasks the model has never seen while still being able to do all these other tasks.
This has just given me a ton of ideas so we’ll probably revisit this soon.